-
Kaggle 캐글 : 타이타닉으로 입문하기(1) - 데이터 탐색 & 전처리Machine Learning 2020. 2. 11. 22:44728x90
1) Titanic 데이터 탐색
1. 기본정보
PassengerId : 승객 ID
Survived: 0은 죽었다는 의미, 1은 생존의 의미
Pclass : 좌석 등급
Name : 승객 이름
Age : 승객 나이
SibSp: 함께 탑승한 형제 자매 또는 배우자의 수
Parch: 함께 탑승한 부모, 아이의 수
Ticket : 티켓 번호
Fare : 티켓 가격
Cabin: 객실 번호
Embarked : 탑승 항구
train=pd.read_csv('/kaggle/input/titanic/train.csv') test=pd.read_csv('/kaggle/input/titanic/test.csv') train.head()
test.head() ## test.csv 에는 survived 칼럼이 없다. 왜냐하면 종속변수이기 때문이다.(예측해야 함)
train.info() ## 총 891개가 있어야 결측값(NaN)이 없는 것이다. 그러나 Age, Cabin, Embarked는 결측값을 가진다.
train.isnull().sum() ## 결측값만 표시하는 방법이다.
test.isnull().sum()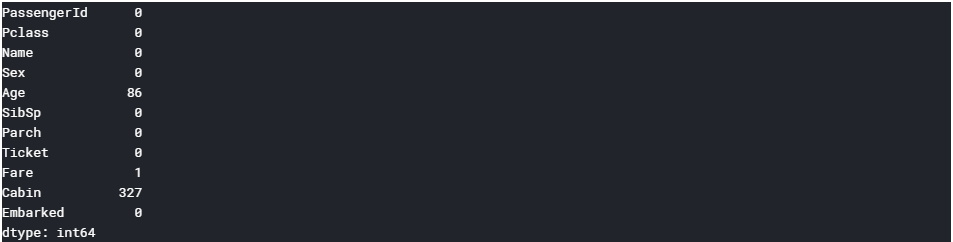
2. 결측치는 데이터를 채울 것인지 버릴 것인지 결정해야한다.
3. 이 과정에서는 필요한 데이터가 무엇인지를 고려해야한다. 필요없는 데이터는 나중에 제거를 할 수 있습니다.
또, 문자열은 숫자로 바꿔야 합니다.
2) 데이터 전처리
import matplotlib.pyplot as plt get_ipython().run_line_magic('matplotlib', 'inline') ## 캐글 노트북을 사용하는 경우에는 다음처럼 매직(magic) 명령으로 노트북 내부에 그림을 표시하도록 지정해야 한다. import seaborn as sns sns.set() ## 그래프 기본스타일 설정1. Name
- 이름은 생존과 관련이 없을 수도 있지만, Mr,Mrs 등 결혼의 유무를 알 수 있는
타이틀은 고려할 사항이 될 수 있습니다.
- 타이틀만 추출하여 Name칼럼은 삭제한다.
train_test_data=[train,test] ## train과 test 데이터셋 합침 train_test_data
for dataset in train_test_data: dataset['Title']=dataset['Name'].str.extract('([A-Za-z]+)\.',expand=False) ## '([A-Za-z]+)\.' :정규표현식 ## 대문자 A-Z로 시작하면서 소문자 a-z가 여러개이면서 마침표 .로 끝나는 것을 추출한다는 의미이다. ## 예로, Braund, Mr. Owen Harris 에서 Mr 를 추출한다는 말train['Title'].value_counts()
test['Title'].value_counts()
1-1. Mr, Miss, Mrs, Master를 제외한 나머지들은 그 수가 너무 적은 것을 알 수 있습니다.
사전적 의미를 따져보면,
Mile, Ms -> Miss
Mme, Lady, Countness, Dona -> Mrs
Major, Col, Sir, Don, Jockheer, Capt -> Mr 로 변경할 수 있습니다.
1-2. 남은 Dr, Rev, Master는 성별을 추측하기 힘드므로 트레이닝 데이터를 확인해봅니다.
train[train['Title']=='Dr']['Sex']
train[train['Title']=='Rev']['Sex']
train[train['Title']=='Master']['Sex']
1-3. Dr 1명 빼곤 모두 male 이므로 저는 셋 다 Mr로 변경하기로 했습니다.
1-4. Mr ->0, Miss ->1, Mrs -> 2 로 매핑합니다.
title_mapping={ 'Don':0, 'Rev':0, 'Capt':0, 'Jonkheer':0, 'Mr':0, 'Dr':0, 'Major':0, 'Col':0, 'Master':0, 'Sir':0, 'Miss':1, 'Mlle':1, 'Ms':1, 'Mrs':2, 'Mme':2, 'Lady':2, 'Countess':2 } for dataset in train_test_data: dataset['Title']=dataset['Title'].map(title_mapping)2. Sex
sex_mapping={'male':0,'female':1} for dataset in train_test_data: dataset['Sex']=dataset['Sex'].map(sex_mapping)2-1. Sex는 남자면 0 여자면 1로 매핑을 했습니다.
3. Age
facet=sns.FacetGrid(train,hue="Survived",aspect=3) facet.map(sns.kdeplot,'Age',shade=True) facet.set(xlim=(0,train['Age'].max())) facet.add_legend()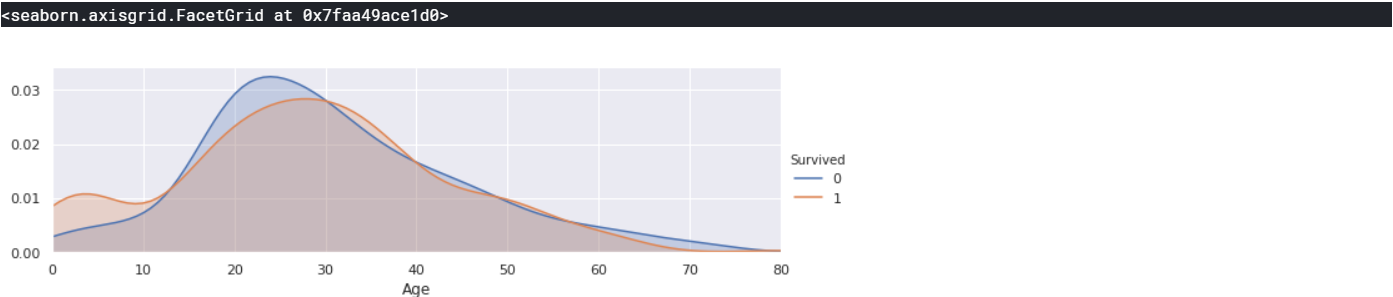
3-1. Age는 177개의 결측치가 있었으므로 데이터를 채울지 버릴지 결정해야합니다.
위 그래프를 보시면 0살에서 약 16살까지는 생존할 확률이 더 높은것을 알 수 있습니다.
반면 20대 중반에서 30대 초반까지는 죽을 확률이 더 높은 것을 알 수 있습니다.
Age가 생존에 여부를 판단하는데 꽤 중요한 변수가 될 것 같습니다.
그리고 그렇기 때문에 결측치를 채워야 할 것 같습니다.
3-2. NAN은 Tilte의 median으로 채울 것입니다.
모두 Mr, Miss, Mrs로 변경하기 전 Title을 이용할 것입니다.
for dataset in train_test_data: dataset['Title2']=dataset['Name'].str.extract('([A-Za-z]+)\.',expand=False) fill=train.groupby('Title2')['Age'].transform('median') train['Age'].fillna(fill,inplace=True) ## Title의 median으로 결측값 채우기 train.isnull().sum() ## 결측값이 사라졌는지 확인
3-3. 결측값을 채웠으니, Age를 10~60를 5단위로 나누었습니다.
for dataset in train_test_data: dataset.loc[ dataset['Age']<=10, 'Age'] = 0, dataset.loc[(dataset['Age']>10)&(dataset['Age']<=16), 'Age'] = 1, dataset.loc[(dataset['Age']>16)&(dataset['Age']<=20), 'Age'] = 2, dataset.loc[(dataset['Age']>20)&(dataset['Age']<=26), 'Age'] = 3, dataset.loc[(dataset['Age']>26)&(dataset['Age']<=30), 'Age'] = 4, dataset.loc[(dataset['Age']>30)&(dataset['Age']<=36), 'Age'] = 5, dataset.loc[(dataset['Age']>36)&(dataset['Age']<=40), 'Age'] = 6, dataset.loc[(dataset['Age']>40)&(dataset['Age']<=46), 'Age'] = 7, dataset.loc[(dataset['Age']>46)&(dataset['Age']<=50), 'Age'] = 8, dataset.loc[(dataset['Age']>50)&(dataset['Age']<=60), 'Age'] = 9, dataset.loc[ dataset['Age']>60, 'Age'] = 104. Embarked
4-1. Embarked 에서 결측치를 가진 행을 추출했습니다.
train[train['Embarked'].isnull()==True]
4-2. 두 사람 모두 SibSp, Parch를 봤을 때 동승자가 없으므로 추측하기 힘들어 가장 빈도수가 높은 값을 넣겠습니다.
train['Embarked'].value_counts()
4-3. S가 가장 많으므로 S로 매핑한 후, 생존율을 확인합니다.문자열을 숫자로 바꾸기 위해 S->0, C->1, Q->2 로 한번 더 매핑하겠습니다.
train['Embarked'].fillna('S',inplace=True) fig = plt.figure(figsize=(15,6)) i=1 for x in train['Embarked'].unique(): fig.add_subplot(3, 6, i) plt.title('Em : {}'.format(x)) train.Survived[train['Embarked'] == x].value_counts().plot(kind='pie') i += 1
4-4. 생존율이 낮은 순으로 매핑하겠습니다.
embarked_mapping={ 'S':0,'Q':1,'C':2 } for dataset in train_test_data: dataset['Embarked']=dataset['Embarked'].map(embarked_mapping)5. SibSp & Parch
5-1. SibSp 와 Parch의 합이 높을 수록 부양가족이 많다는 것을 의미하므로 두개의 합에 따른 생존율을 보겠습니다.
fig = plt.figure(figsize=(15,6)) i=1 for size in train['Family'].unique(): fig.add_subplot(3, 6, i) plt.title('Size : {}'.format(size)) train.Survived[train['Family'] == size].value_counts().plot(kind='pie') i += 1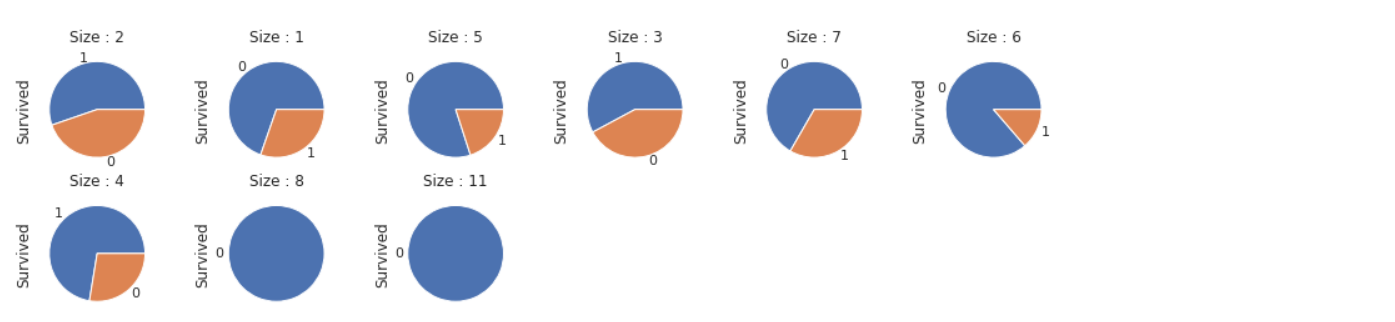
5-2. 생존율이 낮은 순으로 매핑하겠습니다.
family_mapping = { 1: 3, 2: 5, 3: 6, 4: 7, 5: 2, 6: 1, 7: 4, 8: 0, 11: 0 } for dataset in train_test_data: dataset['Family']=dataset['Family'].map(family_mapping)6. Cabin & Fare
6-1. Cabin의 앞글자만 따오기로 합니다.
for dataset in train_test_data: dataset['Cabin']=dataset['Cabin'].str[:1]6-2. 결측값에는 'N'을 넣어줍니다.(그냥 NaN값을 의미함)
train['Cabin'].fillna('N', inplace=True) test['Cabin'].fillna('N', inplace=True)6-3. test의 Fare값의 결측치에는 Cabin의 median으로 채운 후 test의 결측치를 확인한다.
fill=train.groupby('Cabin')['Fare'].transform('median') test['Fare'].fillna(fill,inplace=True) test.isnull().sum()
6-4. Fare 값이 너무 다양하여 범위를 나눠준다.
for dataset in train_test_data: dataset.loc[ dataset['Fare']<=30, 'Fare'] = 0, dataset.loc[(dataset['Fare']>30)&(dataset['Fare']<=80), 'Fare'] = 1, dataset.loc[(dataset['Fare']>80)&(dataset['Fare']<=100), 'Fare'] = 2, dataset.loc[(dataset['Fare']>100), 'Fare'] = 36-5. 아까 Cabin의 값을 'N'으로 넣어준 사람들에게 존재하는 Cabin값으로 넣어주기 위해 각 Cabin별로 어떤 Fare범위가 가장 많은지 확인하고 해당 값으로 'N'값을 대체한다.
fig = plt.figure(figsize=(15,6)) i=1 for x in train['Cabin'].unique(): fig.add_subplot(3, 6, i) plt.title('Cabin : {}'.format(x)) train.Fare[train['Cabin'] == x].value_counts().plot(kind='pie') i += 1
for dataset in train_test_data: dataset.loc[(dataset['Cabin'] == 'N')&(dataset['Fare'] == 0), 'Cabin'] = 'G', dataset.loc[(dataset['Cabin'] == 'N')&(dataset['Fare'] == 1), 'Cabin'] = 'T', dataset.loc[(dataset['Cabin'] == 'N')&(dataset['Fare'] == 2), 'Cabin'] = 'C', dataset.loc[(dataset['Cabin'] == 'N')&(dataset['Fare'] == 3), 'Cabin'] = 'B',6-6. Cabin에 따른 생존률을 비교하여 낮은 순으로 매핑합니다.
fig = plt.figure(figsize=(15,6)) i=1 for x in train['Cabin'].unique(): fig.add_subplot(3, 6, i) plt.title('Cabin : {}'.format(x)) train.Survived[train['Cabin'] == x].value_counts().plot(kind='pie') i += 1
for dataset in train_test_data: dataset.loc[(dataset['Cabin'] == 'G'), 'Cabin'] = 0, dataset.loc[(dataset['Cabin'] == 'C'), 'Cabin'] = 3, dataset.loc[(dataset['Cabin'] == 'E'), 'Cabin'] = 5, dataset.loc[(dataset['Cabin'] == 'T'), 'Cabin'] = 1, dataset.loc[(dataset['Cabin'] == 'D'), 'Cabin'] = 7, dataset.loc[(dataset['Cabin'] == 'A'), 'Cabin'] = 2, dataset.loc[(dataset['Cabin'] == 'B'), 'Cabin'] = 6, dataset.loc[(dataset['Cabin'] == 'F'), 'Cabin'] = 46-7. Fare에 따른 생존율을 비교하여 낮은 순으로 매핑합니다.
fig = plt.figure(figsize=(15,6)) i=1 for x in train['Fare'].unique(): fig.add_subplot(3, 6, i) plt.title('Fare : {}'.format(x)) train.Survived[train['Fare'] == x].value_counts().plot(kind='pie') i += 1
for dataset in train_test_data: dataset.loc[(dataset['Fare'] == 0), 'Fare'] = 0, dataset.loc[(dataset['Fare'] == 1), 'Fare'] = 1, dataset.loc[(dataset['Fare'] == 2), 'Fare'] = 3, dataset.loc[(dataset['Fare'] == 3), 'Fare'] = 27. Pclass
7-1. Pclass에 따른 생존율을 비교하여 낮은 순으로 매핑합니다.
fig = plt.figure(figsize=(15,6)) i=1 for x in train['Pclass'].unique(): fig.add_subplot(3, 6, i) plt.title('Pclass : {}'.format(x)) train.Survived[train['Pclass'] == x].value_counts().plot(kind='pie') i += 1
for dataset in train_test_data: dataset.loc[dataset['Pclass']==3,'Pclass'] = 0 dataset.loc[dataset['Pclass']==2,'Pclass'] = 1 dataset.loc[dataset['Pclass']==1,'Pclass'] = 28. 불필요한 데이터 제거
train.drop(['PassengerId','Name','SibSp','Parch','Title2','Ticket'],axis=1,inplace=True) test.drop(['Name','SibSp','Parch','Title2','Ticket'],axis=1,inplace=True)728x90'Machine Learning' 카테고리의 다른 글
You Only Look Once: Unified, Real-Time Object Detection (0) 2022.07.01 [Python] 이미지 사이즈 변경 (0) 2021.04.11 window에서 darknet 디버깅/빌드 하는 방법 (0) 2021.04.11 openCV를 이용한 motion detection 후 이미지 캡쳐 코드 (0) 2021.02.15 Kaggle 캐글 : 타이타닉으로 입문하기(2) - 여러가지 모델 & 제출 (0) 2020.02.17