-
You Only Look Once: Unified, Real-Time Object DetectionMachine Learning 2022. 7. 1. 16:46728x90
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
Intro
- 최종 출력층에서 bounding box 좌표찾기와 분류가 동시에 이루어짐 ->간단,빠름

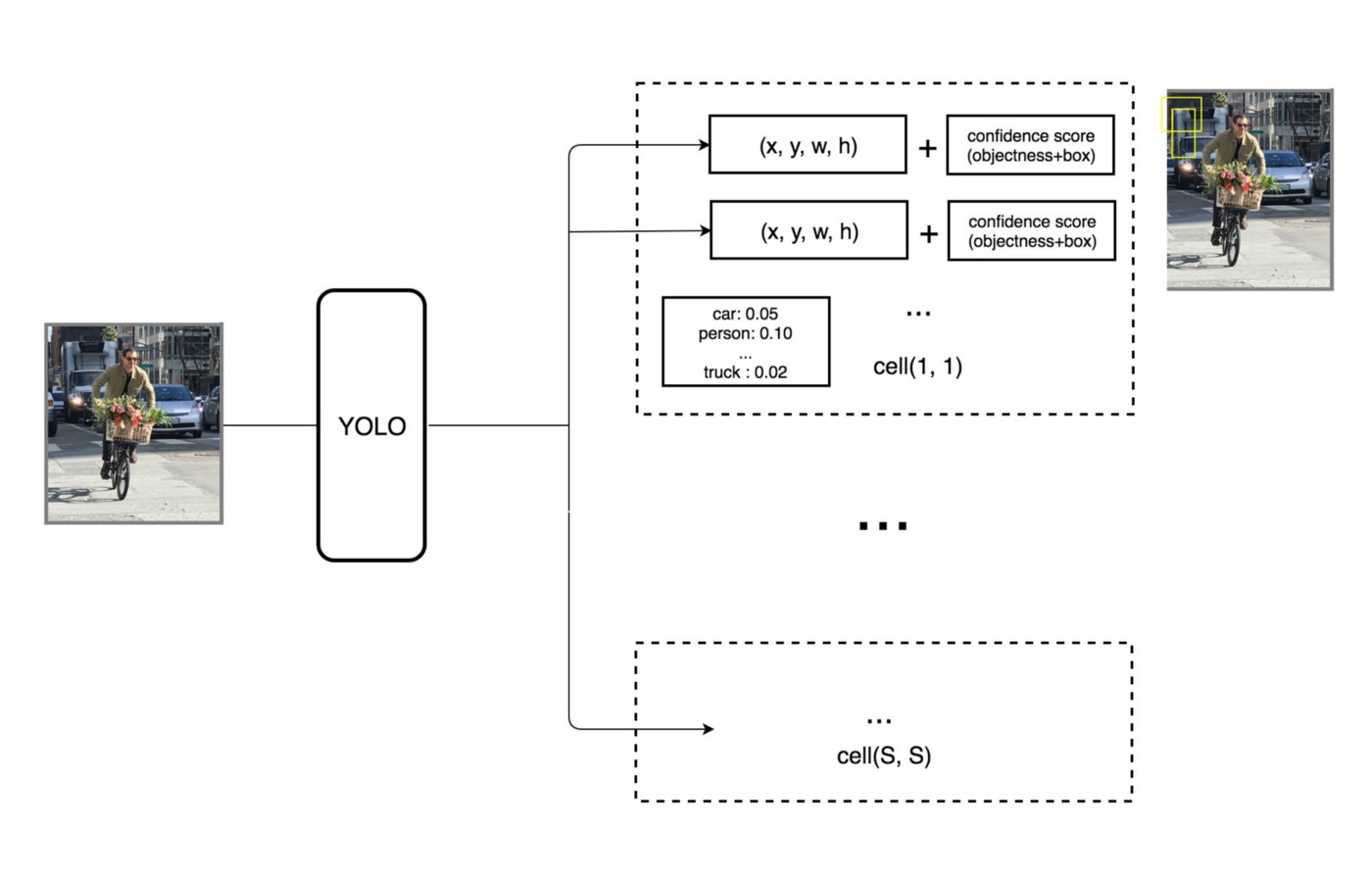
- 영상을 7x7 그리드로 나눈 후 각 그리드 안에 중심이 있는 bounding box를 2개씩 생성 (그리드 셀이 7x7=49개 이므로 bounding box는 총 98개)
- 이 중 confidence score가 높을 수록 박스를 굵게 그림
- Confidence threshold보다 낮은 박스는 지움
- 굵은 박스들 중 NMS 알고리즘을 이용해 선별
- 각 그리드 셀은 해당영역에서 제안한 클래스를 컬러로 표현
네트워크 구조
- 직선적인 구조
- Pretrained : GooglLeNet을 변형시켜 feature추출기로 사용 (20개의 convolution layer)
- Training : convolution layer 4회, full connection layer 2회 후 7x7x30으로 조정
- 마지막 7x7x30이 예측결과
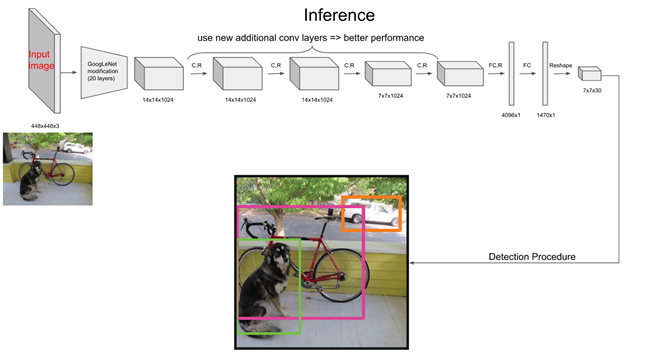
네트워크 예측
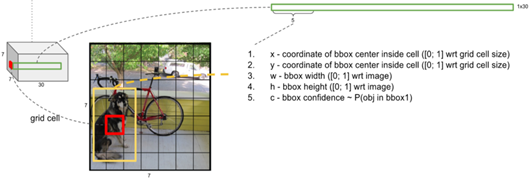


- 노란색 박스(RoI)가 빨간색 그리드 셀에서 예측한 경계박스(RoI 중심이 무조건 빨간박스 안)
- RoI를 2개 만듬
- 따라서 채널은 ((bouding box info 4개+box confidence)x2 +클래스 확률 20개)=30
- Box Confidence는 상자에 개체가 포함될 가능성(objectness)와 경계상자가 얼마나 정확한지를 반영합니다.
- Box threshold값보다 낮은 confidence를 가진 박스는 지움
- Box Confidence 스칼라 값과 클래스 확률을 곱하면 클래스별 confidence나옴
클래스 분류
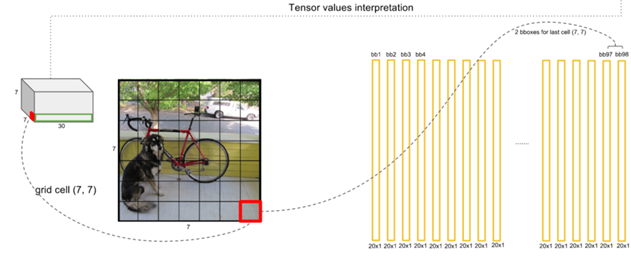

- Bounding box가 7x7개 이므로 class confidence는 7x7x2=98개
- 98개 중 class confidence threshold보다 작은 값은 0으로 채움
bounding box 결정과정


- 클래스의 확률을 높은 값부터 낮은 값으로 정렬
- NMS알고리즘을 사용하여 겹치는 bounding box제거
- 이 과정을 거치면 각 그리드 셀에는 2개의 클래스가 나타날 수 있음 -> 같은 클래스는 나올 수 없는 구조이므로 다른 클래스가 검출될 수 있는데, 오브젝트가 겹쳐있을 확률이 높음
- 각 셀에서 가장 큰 신뢰도를 가진 클래스가 최종 클래스
학습
Loss함수를 보면 네트워크를 어떻게 학습하였는지 파악 가능
- 이미지 분류를 Bbox를 만드는 Regression문제로 생각하여 SSE사용
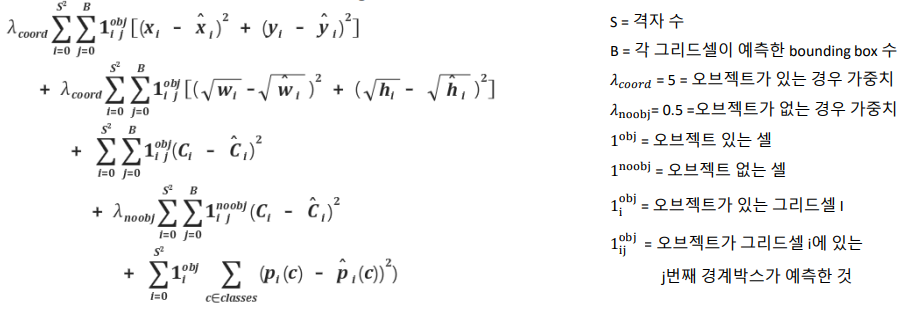
- 대부분의 셀은 오브젝트가 없기 때문에 신뢰점수가 0에 가까워짐 ->오브젝트가 있는 경우 좌표 및 클래스 예측 loss는 키우고 (𝜆𝑐𝑜𝑜𝑟𝑑 = 5) ->오브젝트가 없는 경우는 loss를 줄임(𝜆noobj= 0.5)
- 이렇게 하면 오브젝트가 있는 그리드셀 i에서만 loss가 발생
총 5가지의 loss를 계산
- Bounding box의 x,y 좌표 학습
- 실제로 오브젝트가 그리드셀 i에 있을 때, 예측한 bounding box j가 정답과 같도록 학습
- 그리드셀이 예측하는 2개의 경계박스(j=0,j=1)모두 정답과 같아지도록 유도
2. Bounding box의 width, height 학습
- x,y와 동일하지만 루트를 씌워 사용
- 큰 경계박스에서는 w,h를 조금만 키워도 넓이가 확 증가함 (미분값이 큼)
- sum squared error를 사용하면 박스가 큰 것과 작은 것의 미분차이가 크게 나므로 루트를 씌움
3. 그리드 셀 i에 오브젝트가 있을 경우 클래스 예측
- 오브젝트가 무엇인지 예측
4. 그리드 셀 i에 오브젝트가 없을 경우 클래스 예측
- 낮은 가중치를 곱하므로써 오브젝트가 있는 셀이 더 정확히 클래스 분류를 하도록 도움
5. 클래스 확률
- B에 대한 sum이 없다.
- 각 그리드 셀 i에서 bounding box는 2번 예측하지만 클래스 확률 c는 공유하기 때문 (같은 클래스는 나올 수 없는 구조)

코드로 표현하면 이런식
정리
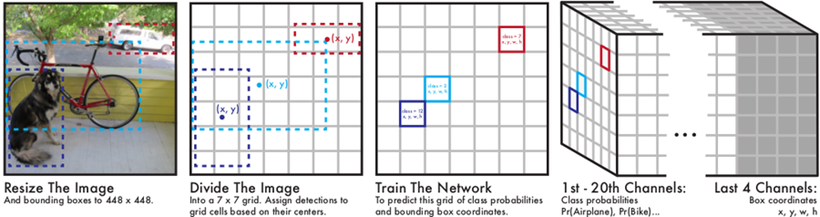

- RGB 이미지 입력데이터
- Ground Truth
- 전체 좌표를 7x7그리드 셀로 나눈 후, 각 셀의 클래스와 bounding box정보를 저장
3. 네트워크 학습
- 각 셀에 오브젝트가 있는지 (confidence), 있다면 어떤 클래스인지와 bounding box정보 저장
4. 실제 네트워크 출력
한계
- YOLO는 각 그리드 셀을 중심으로 bounding box를 2개, 하나의 class를 가짐
- R-CNN계열은 후보를 천개이상 제안하는 것에 비해 너무 적으므로 성능이 떨어짐
- 그래서 한 오브젝트 주변에 여러 개의 오브젝트가 있을 때 검출을 잘 못함
- 같은 이유로 셀 하나에 오브젝트가 여러 개 있어도 2개밖에 검출을 하지 못함
- 작은 Bbox와 큰 Bbox에서의 error를 동일하게 적용하므로 localization이 부정확한 경우가 발생
- Bbox의 형태가 training data를 통해 학습되었기 때문에 새롭거나 비율이 특이한 object가 들어오면 generalize하는 데 어려움이 있음
728x90'Machine Learning' 카테고리의 다른 글
ML을 시작하는 사람들을 위해 (1) (0) 2023.12.22 Linear Regression (0) 2022.07.11 [Python] 이미지 사이즈 변경 (0) 2021.04.11 window에서 darknet 디버깅/빌드 하는 방법 (0) 2021.04.11 openCV를 이용한 motion detection 후 이미지 캡쳐 코드 (0) 2021.02.15